
What Are Artificial Neural Networks — and Why They’re the Heart of AI
Artificial Neural Networks explained in simple terms — with a tiny numeric example, practical tips, and a clear roadmap for beginners.
The 10-second version
Artificial Neural Networks (ANNs) are computer models inspired by the brain. They learn patterns from data by adjusting numbers called weights and biases. These models power many AI tasks image recognition, speech, recommendations and they’re the foundation for more advanced architectures like CNNs and Transformers.
1. A very human analogy first
Imagine teaching a friend to spot ripe mangoes. At first they mess up. With every example this one is ripe, that one is not they rewire what cues they pay attention to (colour, softness, smell). Over time they get better.
An ANN does the same thing, but with math. It looks at examples, measures errors, and adjusts internal knobs until its guesses improve. Not magic just iterative learning. And honestly, that iterative part is the satisfying bit.
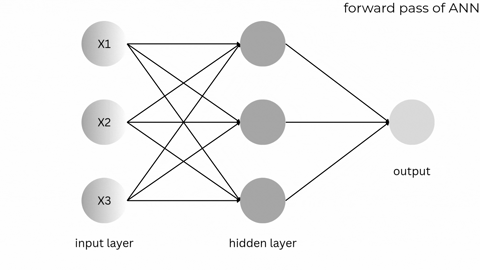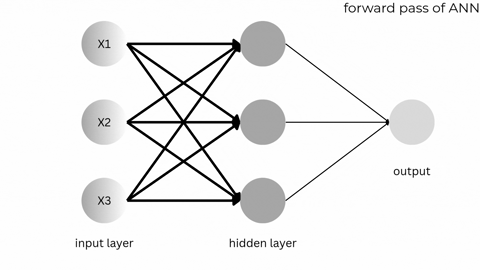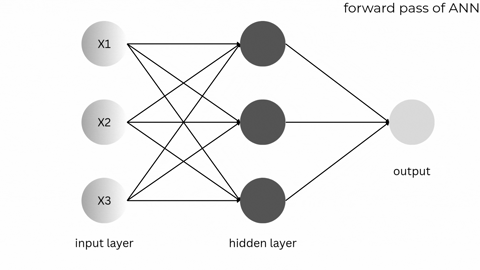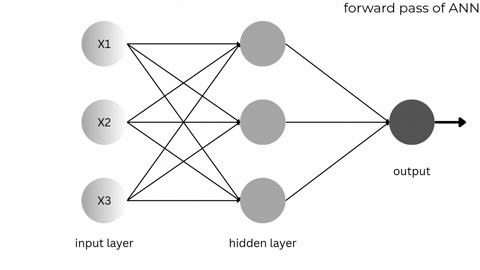
2. The building blocks: neurons, layers, and connections
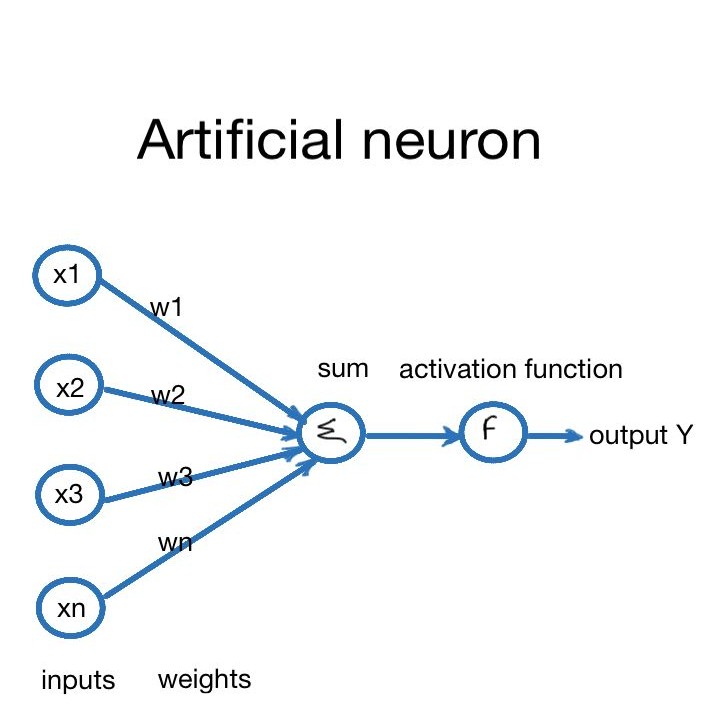
Neuron – the smallest unit
A neuron in an ANN is a tiny calculator that:
- Accepts inputs (numbers).
- Multiplies each input by a weight (how important it is).
- Adds a bias (a small tweak).
- Runs the sum through an activation function (gives the neuron a useful response).
Layers
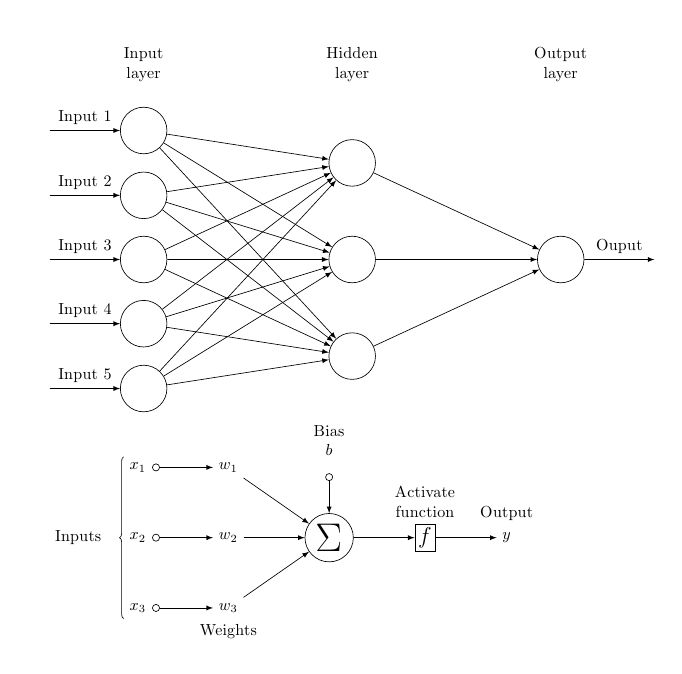
Layers stack neurons. There are three common types:
- Input layer – where raw data (pixels, words, features) enters.
- Hidden layers – where the model learns intermediate representations.
- Output layer – the final prediction or score.
More hidden layers = deeper network. Hence the term “deep learning.”
Connections and weights
Each connection has a weight. High weight = that input matters a lot. Weight near zero = mostly ignored. The entire training process is about finding useful weights.
3. A tiny numeric example (forward pass)
Numbers make things less fuzzy. Let’s run one neuron with two inputs so you see what happens under the hood.
Inputs:
x1 = 0.5, x2 = 0.8
Weights:
w1 = 0.4, w2 = 0.9
Bias:
b = -0.1
Activation:
sigmoid
Compute:
x1*w1 = 0.5 * 0.4 = 0.20
x2*w2 = 0.8 * 0.9 = 0.72
Sum + bias = 0.20 + 0.72 + (-0.1) = 0.82
Output = sigmoid(0.82) ≈ 0.694The neuron outputs ≈ 0.694. If this were a yes/no classifier, you might read that as ~69% confident in the “yes” class. Little numbers, big feeling.
4. Training: how the network actually learns
Loss function — the scoreboard
You need to know how wrong the model is. That’s the loss. Bigger loss = worse. Examples: mean squared error, cross-entropy.
Backpropagation — telling the network what to change
Backpropagation is a clever bookkeeping trick from calculus. It figures out how much each weight contributed to the error. Then we know what to tweak.
Gradient descent — the slow, steady optimizer
With the gradient in hand, we take tiny steps in the direction that reduces loss. Repeat. Over many examples and many steps, the network gets better. Picture hiking downhill blindfolded, but you can feel the slope — small steps, and eventually you find the valley.
5. Why ANNs are so powerful
A few reasons:
- They learn features automatically. No more hand-crafting everything.
- Universal approximators. Theoretically, big enough networks can approximate complicated functions.
- They scale. Give them more data and compute and, more often than not, they improve.
Of course, that power asks for tradeoffs: more data, more compute, more care to avoid overfitting.
6. Common beginner pitfalls (and quick fixes)
- Too deep too soon. Start small, then grow the model.
- Not normalizing inputs. Scale your features so the network trains faster and more stably.
- Overfitting. If training accuracy is great but validation accuracy is poor, try dropout, regularization, or more data.
- Blindly using defaults. Learning rate, batch size, optimizer – they matter. Tweak and record.
7. Where ANNs are used (real-world examples)
From photo tagging to voice assistants — ANNs are everywhere. A short list:
- Image recognition (face ID, photo search)
- Speech recognition (phone assistants)
- Recommendation systems (streaming platforms)
- Medical imaging (assisting doctors)
- Finance (fraud detection)
8. Short roadmap: ANN → what’s next
If you’re starting, follow this order:
- Understand single neurons and perceptrons.
- Build a tiny ANN (one hidden layer) in NumPy.
- Try Keras/TensorFlow or PyTorch with MNIST.
- Learn regularization, optimizers, debugging.
- Move to specialized models: CNNs for images, Transformers for text.
Each step rewards you with a better mental model. I promise it gets more fun and messy in a good way.
Key terms — mini glossary
Weight: importance of an input.
Bias: an extra adjuster.
Activation: function that shapes a neuron’s output.
Loss: measure of error.
Backprop: algorithm to compute gradients.
Gradient descent: updating weights to reduce loss


Furthermore, the support team is both knowledgeable and friendly, making interactions pleasant.